Understanding Machine Learning and AI
Defining the Current Landscape
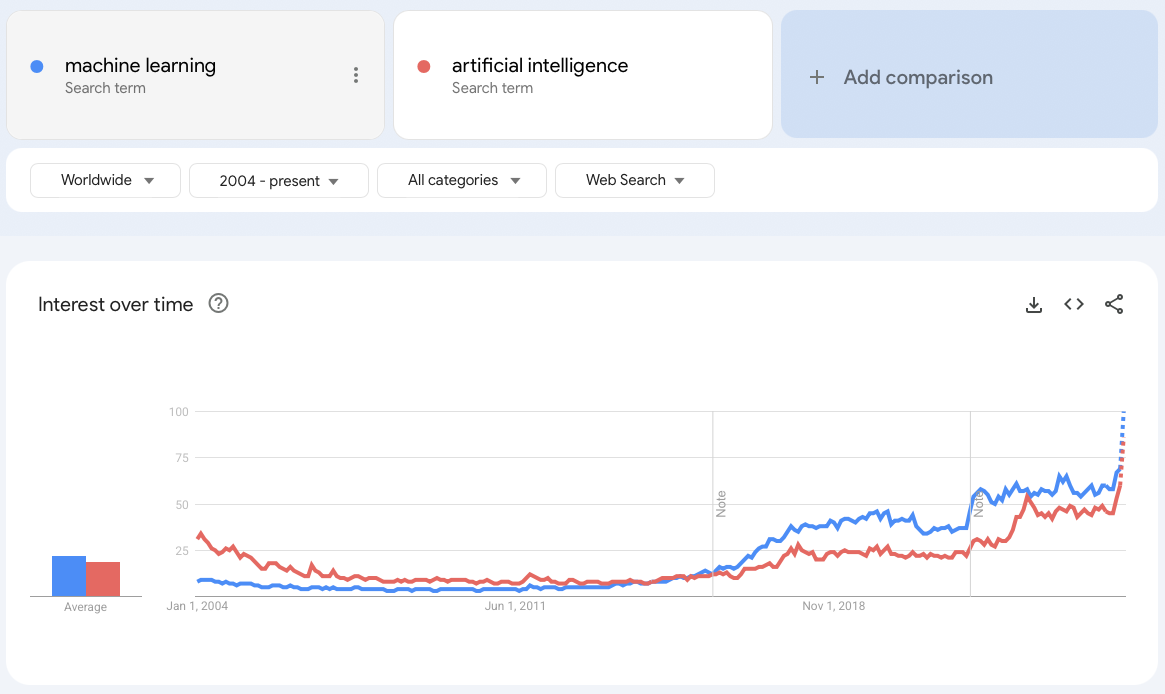
Machine learning & Artificial Intelligence has rapidly evolved from an academic concept to a mainstream business tool. Google Trends data reveals exponential growth in search interest since 2004, indicating both early adoption by innovators and recent mainstream acceptance.
Facets of Machine Learning Surround Us Everywhere
 As a business leader, you likely encounter machine learning applications daily without realizing it. Netflix's content recommendations, Spotify's music suggestions, and even medical diagnostics using retinal imaging for cardiovascular risk assessment all demonstrate machine learning as examples in practical application.
As a business leader, you likely encounter machine learning applications daily without realizing it. Netflix's content recommendations, Spotify's music suggestions, and even medical diagnostics using retinal imaging for cardiovascular risk assessment all demonstrate machine learning as examples in practical application.
What is Machine Learning?
So how do all of these companies make intelligent decisions and recommendations? How can they find these patterns in enormous troves of data?
The answer lies in a combination of pattern recognition in data, being able to make predictions based on the patterns, getting better at making these predictions and automating this process. Let’s examine all four of these elements.
Pattern Recognition: Identifying meaningful relationships in data
Predictive Capability: Making informed predictions about future outcomes
Adaptive Learning: Improving accuracy as more data becomes available
Automation: Reducing human intervention in decision-making processes
Pattern Recognition
There is no magic number of how much data is the right amount of data in order for a ML/AI system to be able to recognize patterns. But the general rule is more data is better than less data. More usage of a product is better than less usage. The more you interact with an application, and the larger the number of users that interact with a program, the smarter it gets.
But if you insist on an answer, then we would refer to an explanation from Prof. Yaser Abu-Mostafa from Caltech. The professor was asked, in his online course, about the amount of data required for a Machine Learning algorithm. The professor stated - as a criterion, we need 10 times as many examples as there are degrees of freedom ([https://www.investopedia.com/terms/d/degrees-of-freedom.asp) in our machine learning model. Degrees of Freedom refers to the maximum number of logically independent values, which are values that have the freedom to vary, in the data sample.
In a straightforward linear model, the degrees of freedom corresponds to the dimensionality of data (number of columns).
The ‘more data is better than less data’ is not immune to the law of common sense. Machine Learning can be influenced if the input variables are not truly independent as well.
Generally a larger data set allows for testing multiple approaches (statistical models) to find patterns in a data set.
Predictive Capability
The predictive capability of an algorithm should not be determined purely based on mathematical accuracy.
Data elements should also pass a sanity check to ensure that the predictive capability is grounded in the reality of the business. And for that we must ensure that all the data elements (attributes) are relevant.
You can think of attributes as different data points or elements of data. Normally, the more of these you have, the richer your data is.
Imagine if you are an airline. In all likelihood, you have access to arrival and destination cities, credit card type, the website used to book the ticket, date, time, device, day of the week, address of the purchaser, age, number of accompanying passengers, etc. With these, you can create a persona of the different kinds of customers. But an even richer profile can be built by adding external data like key events at destination cities (festivals, sports events, concerts, weather, statutory holidays, school holidays etc.). All of these are “attributes” of a single object which is the airline ticket.
With the advantage of scale of data for pattern recognition and predictive capability grounded in critical attributes, you can explore and look for surprising relationships between independent variables and dependent variables. Finding, testing, and validating these relationships can lead to deep and actionable insights.
Adaptive Learning
There was a time when large amounts of data crunching was the prerogative of large corporations with vast resources. With the rapid adoption of on-demand computing resources, almost anyone can now get the computing resources required. All large technology companies like Google, Microsoft, Amazon have robust cloud computing offers.
With the benefit of cloud infrastructure, you can now constantly re-train the data as it refreshes to ensure that the model is always learning and improving its ability to predict.
Automation
All models, those that are independent or dependent on others can easily run on an automated basis.
What is not Machine Learning?
The end goal of Machine Learning is ‘prediction’. Therefore any number-crunching that does not rely on statistical learning from a pre-existing data set or does not build towards the goal of "prediction, is not Machine Learning. Thus, you being targeted by an ad as you wander across the web is not Machine Learning. That is probably an example of you being retargeted by a merchant website that you visited but did not take an action that a merchant wants website visitors to undertake. If you begin to see ads from a physical retail store that you visited, chances are that you are retargeted because the merchant is serving ads based on some kind of location technology. If you logged into the store wifi, then you are not really being targeted because of Machine Learning (although Machine Learning may have been used in some shape or form along the way).
But if you are re-targeted based on some learnings from a large data set of previous users that were re-targeted, then that is an example of machine learning being applied in the real world.
People often think of Machine Learning as AI (Artificial Intelligence) or use the terms interchangeably. While Machine Learning is a subset of AI, AI is not Machine Learning. AI has a much higher purpose in life. It aims to emulate some of the creative faculties of humans.
Machine Learning is also not ‘Deep Learning’. Much of ‘Machine Learning’ data is labelled, and this training data (or sample labelled data) is what the algorithm trains (learns) itself on. In Deep Learning, there is no training data. The self-learning algorithm directly interacts with the unlabeled data.

Artificial Intelligence In Increasing Stage of Complexity (from left to right)
Some Machine Learning Terminology
Independent Variable - The variable that has an impact on the dependent variable. This independent variable (or input variable) is usually plotted on the x-axis
Dependent Variable - This is the target (or output) variable is what the model will try and predict. This is usually plotted on the y-axis. You can have more than 1 y-axis.
Feature - Multiple input variables that may be having an impact on the target/output variable
Label - The output variable that the algorithm will try and predict.