Make your organization Machine Learning ready.
We know that Machine Learning contributes significantly to organizational growth. The organization, its stakeholders, employees, and management all have to learn and contribute to the implementation of Machine Learning models. We have prepared a checklist which can help you to prepare yourself and your team for Machine Learning implementation.
 Visual Checklist to determine if your organization is ready for Machine Learning
Visual Checklist to determine if your organization is ready for Machine Learning
Do you have a clear problem statement that needs to be solved using AI/ML?
Machine Learning is mostly used for prediction and clustering purposes. So, the first step is to identify the problem statement that may equate to something like “what you want to predict?” or “How many clusters do you want to create”.
Organizations need to have a clear problem statement to utilize machine learning.
For example- which customers are responding to the promotional offers and which ones are not, or we need to predict the right treatment plan for a patient so that his/her health outcomes become better by 20%.
Do you have the right data?
The next step is to identify relevant and reliable data as per our problem statements. We need to check the right data which means it should be collected from a trusted system and all information related to the problem statement needs to be accessible.
The time-series (data points that are spaced out by equal units of time) data set always performs better than a static dataset for machine learning algorithms. Sometimes you need to enrich your existing data sets by merging information to make it ready as input to an algorithm.
Do you have any/enough data?
We have already discussed how machine learning requires a lot of data. We can also classify the data that into three categories depending on where it originates from:
A. First-party data sources or internal/proprietary data
B. Second-party data sources or external data (data from partners or suppliers)
C. Third-party data sources
First-Party Data Sources
First-party data is the type of data that you gather from directly engaging with the audience. It can be data collected from website cookies, customer transaction history, form submissions, or your customer service center. This type of data has some specific advantages:
The first-party data that you collect gives you insightful details about your customer’s behavior.
It is accurate and relevant since it is gathered directly from your customers.
You own this data
For example, Netflix has created a direct relationship with its audience. It knows how their audience interacts with their content and hence Netflix enhances the user experience on a consistent basis.
There is a great case study of Netflix regarding the series ‘House of Cards’. While the general practice of the TV industry was to intrigue the audience by commissioning a few pilot episodes, Netflix commissioned two entire seasons of the show for $100+ million. Why did Netflix gamble on the show? Well, the answer lies in what we discussed above: first-party data. By analyzing the data of 33 million subscribers at that time, they knew that their audience liked David Fincher’s work or streamed movies featuring Kevin Spacey. And they were right. Within three months of introducing the show, Netflix added 2 million subscribers!
In the case of our grocery store example, here is a list of some first-party data sources that the grocery store would be able to collect:
A. Data from the POS system as customers purchase products, method of payment (travel cards versus cash back cards versus debit cards etc.) used, day and time of the purchase etc.
B. If the store offers free Wi-Fi, there is an opportunity to collect some additional web data
C. If the store has some cameras that can scrub out the faces of the customers, generate heat maps of where the customers linger longer and use that information for better merchandising
D. Where stores have their own loyalty program, the data can be traced back to an individual for better and richer profiles
E. Where the stores have their own recipe app or shopping lists app, the grocery chain would be able to tap into that data too
Second-Party Data Sources
Second-party data is the data collected from some other organization like a supplier brand, or supplier website, for the mutual benefit of both businesses. This data is merely somebody else’s first-party data. This type of data is helpful only when the company is relevant to your audience.
Some of the advantages include:
A. A more contextual understanding of its customers
B. Potential competitive market advantage
C. The possibility of predicting behavior with greater accuracy
Let’s say you are running an online cosmetic store targeted at women. Your first-party data comes mostly from women. Now, if you want to introduce a men’s product, you won’t have the first-party data for it to reach your audience. In this case, you can team up with a men’s health website and get the data from them.
In the case of our hypothetical grocery store, they may be a partner of a larger points program. Through this partnership, the grocery store may be able to understand the behavior of its customers in terms of what non-grocery items they like to consume.
Potential Use Cases:
A. If a grocery can determine that their customers like to travel to specific countries for vacations, perhaps they can incorporate those themes into the store flyer and store merchandising
B. If a grocery can determine that their customer base has specific tastes in movies, music, travel, etc., all of that can assist with the creation of a richer persona.
C. If a grocery can see other elements of the lifestyle of their customers, they could improve their advertising messaging.
Third-Party Data Sources
Third-party data is the data collected from organizations that do not have a direct relationship with your customers. Sometimes, we have to buy this data. There are market research organizations that collect data from different sources for different industries and markets. You need to buy it to understand market trends and competitors. Some of the advantages of having third-party data are:
Identifying potential new customers
Expanding your audience
Data sourced from independent surveys, polls, etc., would constitute third-party data sources. Our hypothetical grocery store could buy such data (provided all privacy concerns are addressed in the Rules & Regulations under which such data was collected). They can match the name and address of the survey respondents with their first party database, and create a more vibrant profile of their customers.
Matching and Merging the data
It is nice to have a combination of all three types of data. Machine Learning is only as good as the data that it used for training purposes. By combining first, second and third-party data, we can have a complete view of our customer’s journey on and beyond our channels. It is also very obvious that we may not need all the information for the Machine Learning model but it can be useful for other business strategies. We need to match and merge data based on our input and output variable.
Netflix also monitors social media for ongoing conversations where there may be room for it to add to the conversation.
While it may not be able to identify social media users in its database, this is an extension of using clusters of relevant customers/prospects wherever it may find them.
How organized is your data and In how many distinct systems does your data reside?
A survey in 2019 that targeted 200 IT, data science, and data engineering professionals at North American organizations with at least 1,000 employees found that the mean number of data sources per organization is 400 sources. More than 20 per cent of companies surveyed were drawing from 1,000 or more data sources to feed BI (Business Intelligence) and analytics systems.
An Average Fortune 1000 company has around 48 applications and 14 databases for a total of 62 potential systems that it can integrate. Chances are that your corporation is no different.
Take our hypothetical grocery as an example:
A. Products purchased by customers are in the POS (Point of Sale) system
B. Customer demographics and shopping frequency etc. are likely in the CRM (Customer Relationship Management) system
C. The suppliers are probably dealt with through some ERP (Enterprise resource planning) system
D. In-store inventory, returns, etc. are in some other system with a tie into the supplier systems for re-ordering
E. Historical pricing information may be in some other system
For the Machine Learning algorithm to take into account and test various variables, it is critical to:
A. Provide it with access to all these relevant data sources and elements
B. Ensure that the algorithm will have access to all such data sources on an ongoing basis so that the data never goes stale.
How frequently does your data get updated?
Every organization is different and they have a different time frame to update their data. And we know data is very crucial for our Machine Learning model to produce a highly accurate result. Training your machine learning model and then deploying it is not a one-time thing. It continuously needs to be updated because the surrounding environment always changes. Weather, holidays, long weekends, and the school year can all impact customer buying behaviors. So, new data needs to be fed to the model to maintain its predictive accuracy. Imagine applying NLP (Natural Language Processing) to a chatbot from the language model used in the 1980s. Language evolves. Pronunciations change, meanings of words drift, and so for a modern chatbot, the model needs to be fed to the new language.
There are two ways to keep your model updated:
Manual approach
Continuous approach
Manual approach
This approach consists of training the model again with the new data. This process can be time-consuming, of course. With such an approach, a business may only find out too late that the ground underneath its feet has shifted already.
Continuous approach
This approach incorporates new data streams into the model continuously. For example, Spotify uses collaborative filtering to provide recommendations to its users based on the preferences of users with similar tastes. So the data is fed back to their models’ algorithm and thus refines the user experience. Netflix also uses the same strategy for the continuous learning of their systems.
In what format(s) is the data?
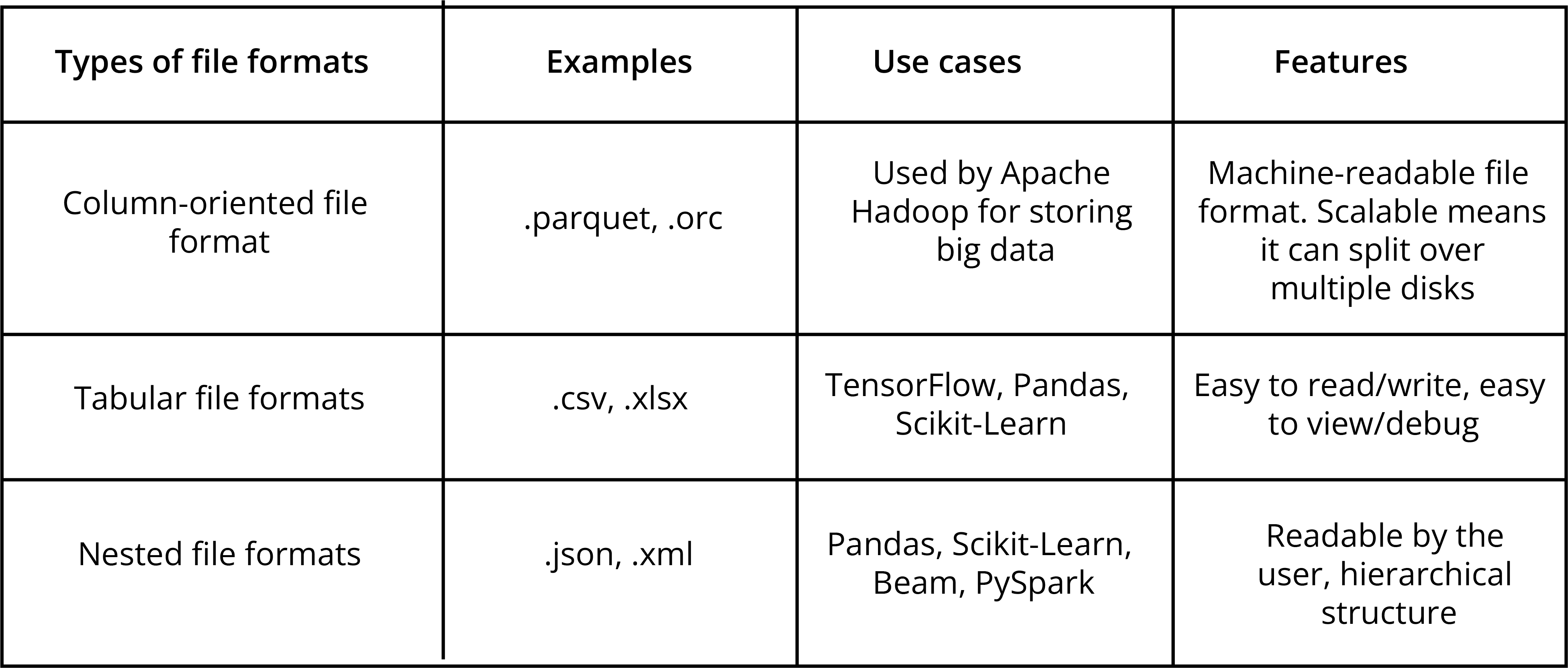
There are multiple ways of storing data, so the data formats vary greatly. We need to understand file structure and data format because we have to combine all the data and make a single data table for the Machine Learning Model.
Data format represents how the data is stored in memory. The enterprise data is mostly in some database, and it is accessed through SQL. Various file formats are available that are used interchangeably for optimizing their data. We will have a brief overview below for some of them.
Do you have the expertise and resources required?
The expertise and resources required to deploy a machine learning model generally depend on two factors:
A. People
B. Hardware
People
Having the right skill set of people in your team is as equally important as the algorithm you choose. We need not only data scientists and engineers but also business analysts since we are working on a business problem at hand. Data Scientists can take care of data science-related issues but they may not have the domain knowledge required for Machine Learning. Our goal is the automation and ongoing maintenance of the business process or system.
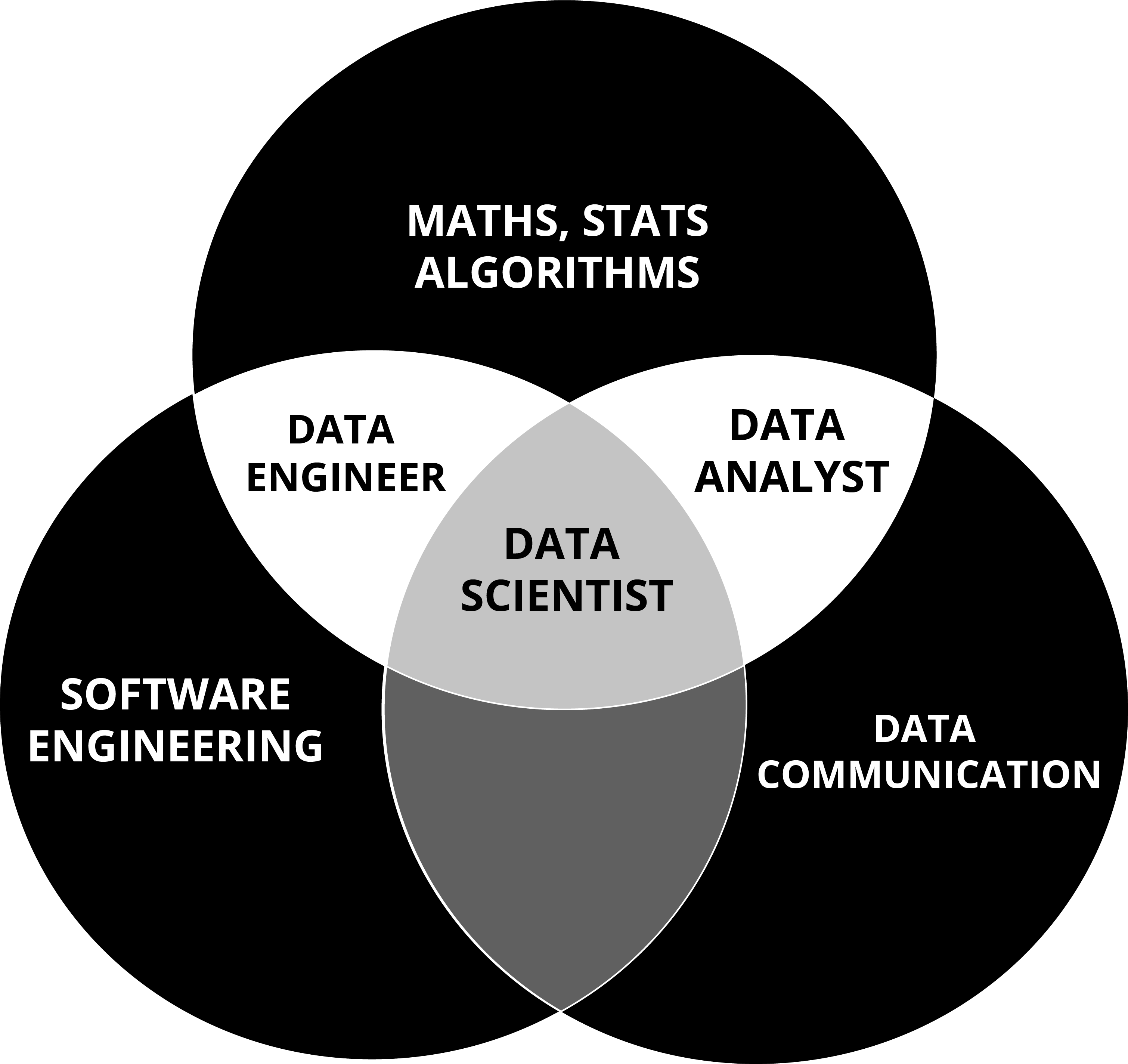
Data Engineer
As we discussed before in the data-gathering section, the output of the machine learning algorithm depends on the depth and breadth of data. Data engineers are responsible for integrating these data into the machine learning model. Data Engineers look at data availability, data hygiene, and data refresh routines to ensure new data keep flowing in, providing a methodology to estimate any missing data so that the algorithm does not assume missing data to be an actual outcome.
Data Scientist
Data scientists explore data to extract features critical for making business decisions. They often guide engineers on how to structure the business model according to the appropriate metrics.
DevOps Engineer
Development and operations engineers collectively referred to as DevOps engineers are responsible for the deployment and maintenance of the model. They have to interact with engineers and data scientists to ensure the smooth working of the model. All infrastructural needs are addressed by them.
Business Analyst
Business analysts look at the data provided by the data scientists and analyze business use cases to know where their model can add value to the organization.
The main obstacle that organizations face in implementing their business model is the gap that exists between data engineers and business analysts.
Do you have the infrastructure?
There are four steps involved in preparing the ML model from an operational perspective.
Gathering and processing the data
Training the learning model
Storing the learning model
Deployment of the model
Among these, training the model is the most intensive task in terms of computational power. It is where CPUs, GPUs, and TPUs come to play.

CPU
A CPU or Central Processing Unit is the brain of any computing device and is generally used to compute complex calculations. They are applicable for fast parsing or performing complex logic. So, if our machine learning task is small and only needs to handle complex calculations sequentially, we can safely use CPUs.
A CPU such as i7–7500U can train an average of ~115 examples/second. But when things get a little intensive, we might consider using a GPU.
GPU
A GPU or Graphical Processing Unit works opposite to a CPU. It performs calculations in parallel and has excellent processing power. A GPU has been popular with gaming applications and graphic engines. So, if your machine learning task is intensive, GPU would be a better choice to use. Laptops with a high graphics card like Nvidia GTX 1080 (8 GB VRAM) can train an average of ~14k examples/second.
TPU
TPU or a Tensor Processing Unit is an application-specific integrated circuit (ASIC) which is designed by Google for its machine learning framework. Google Search, Google Photos, and Google Translate all use TPU. A TPU can deliver 15-30x better performance than a CPU or a GPU.
If your project needs TPU’s for computing power, you will likely need to use an external cloud service.
Do you have corporate buy-in?
The end goal of a Machine Learning team is to find new insights, accelerate existing processes, or confirm/disprove existing insights. In the case of new insights, a business must be prepared to act on those insights. Parking the findings even for a few months, may in some cases, make the algorithm and its findings outdated.
Change can be uncomfortable. Understanding the math behind the exact working of an algorithm can be daunting. But if there is buy-in at the top leadership level in a ‘better’ way of doing things, then the organization is ready for change.
Crawl, Walk & Run
Starting down the path of ML and AI, organizations should keep the mantra of “crawl, walk, and run” in mind. The organizations that are succeeding in ML are utilizing some basic formulas. They are harnessing new sources of data while improving the algorithm’s performance. Your goals may not be to use AI to create something new but rather accelerate your business’ momentum.
The following quote from Dr. Martin Luther King Jr. is apt for the Machine Learning journey:
“If you can’t fly then run, if you can’t run then walk, if you can’t walk then crawl, but whatever you do you have to keep moving forward.”
Improving Analysis
One feasible way is to invest in software usage analytics. Tracking user interaction with the model is an efficient way to collect data about outcomes and also correct the issues faced. It may also help organizations fine-tune their feature sets.
The Right Team
As discussed before, we need a team of not only data scientists and engineers but also business experts. We need all of them to work together. Having a diverse set of skills and providing them with an appropriate learning environment for analytics plays a crucial role.
A Unified Data System
When an organization merges all types of data into a single system, it is called a unified data system. It allows us to see a complete picture of the company’s data and provides flexibility to work with data of different formats. Enabling this is a giant step in the journey to make the Machine Learning process and program a success.
Machine Learning is not a one-and-done exercise
Take the case of our hypothetical grocery store. On an overall basis, the consumption pattern may not differ too much year over year. Consumption patterns based on Superbowl Sunday in 2023 may be quite similar to Superbowl Sunday in 2024, and the same may be true for Back to School for a year over year.
But when it comes to clusters of customers identified by a Machine Learning algorithm, the goal should be to spot folks that are more open to vegan Superbowl Sunday ingredients, etc. or folks that no longer have school-going kids. The job of the machine program is to provide inputs for the best possible outcome at each touchpoint for the customer.
Projects that are AI and big data-based have a high failure rate. 87% of data science projects never makes it to production. 77% of businesses report that the adoption of Big Data and AI initiatives represent a challenge. With such high failure rates, crawl, walk, and run is the best way to move forward unless an enterprise is facing an existential threat.