Myth Buster Section
In this chapter, we are going to discuss 7 Machine Learning myths that are misconceptions and need to be cleared up.
Myth 1: Machine Learning can do anything with massive amounts of data
There is a general perception regarding the data for ML, which is “the more, the better”. Although we have discussed in our previous chapters about the amount of data we may need, we also mentioned the importance of having “relevant and clean” data.
We need sufficient data and high processing power systems for our ML model to train, so that it produces a model with a high degree of accuracy when it comes to prediction. Specifically, Deep Learning models and NLP models require millions of records to be trained. But these data elements must be relevant and clean, otherwise, our ML model will be unable to generate the result that we are expecting.
There isn't going to be any significant positive impact on your ML model if the data is messy and irrelevant to the problem at hand. Sometimes, it can even harm the performance of your model.
Let us discuss a use case in robot reasoning trained with lesser data.
You probably have seen CAPTCHAS on websites to determine whether you are a human or a robot. Researchers have developed models that can break those CAPTCHAS with 67% accuracy using only 5 training examples.
So, having mountains of data is NOT all the rage; having cleaner data is.
Myth 2: Machine Learning is about computer programs learning to think like a human brain.
Us humans have some physical and emotional limitations when it comes to our brains. We are biased and emotional sometimes while making decisions and can make mistakes when analyzing tremendous amounts of data. But computer programs have no physical or emotional limitations. Our Machine Learning algorithms can pick up on these biases if these are baked into our training data.
ML identifies the intricate patterns and analyzes the data better than humans. Here is an example that can clarify this phenomenon.
Researchers at the National Institute of Health and Global Good developed an AI model that can analyze the digital images and diagnose cervical cancer symptoms, which may go undetected by human experts.
In a project initiated by Google called AutoML, they made a machine learning software that can teach other ML software. The system was successful at categorizing objects in an image by 43 percent, while the humans scored 39 percent.
Myth 3: Machine Learning Can Work Independently Without Human Intervention
Humans build the algorithms and the techniques used to develop a machine learning model. Providing cleaner data in its proper format and continuously updating the dataset is something that requires human intervention.
Machine Learning algorithms cannot work independently. We need Data Scientists for decision-making and to avoid new risks that algorithms introduce. We need human intervention to test and re-train the model with new data and new algorithms.
We also need human intervention to do feature engineering and derive new features, which would have more significance in data modelling. These researchers tell the model what to learn, how to learn, how the model and findings should be deployed, and evaluated. Fine-tuning the weights in a deep learning network to find the best model also requires the supervision of experts.
Myth 4: Machine Learning Will Take Over Human Work
Yes, machine learning is going to replace humans for many tasks. For example, robots work in Amazon warehouses to move things around for picking and packing items. Every 10-15 years, old skills and talent gets replaced with new skills and talent. This is the same trend in ML and AI. Erik Brynjolfsson, Director of the MIT Center for Digital Business, says:
“Managers who know how to use machine learning will replace managers who don’t”. And we hear the very same thing now with AI.
This is going to be the winning mantra. The modern digital revolution requires humans and machines to work side by side: using machine learning to automate business processes and using the interpersonal skills of humans to take businesses to the next step is what will set the winners apart from the others.
We need to be decision-makers and input providers to our models.
Myth 5: Machine learning can predict the future
Machine learning models are fed with the historical data to train, based on which it predicts future unseen instances. It can generate insightful results in business or can recommend products, services or entertainments according to a person’s past experience and profiles.
But right now, AI is not in the best position to predict the uncertain future or any black swan events. For example, it cannot predict the sales of a particular product when the world gets hit by the COVID-19 pandemic because the past data did not look like the present.
Also, it still lacks the creative thinking ability of humans despite the availability of large amounts of data and math-based technology.
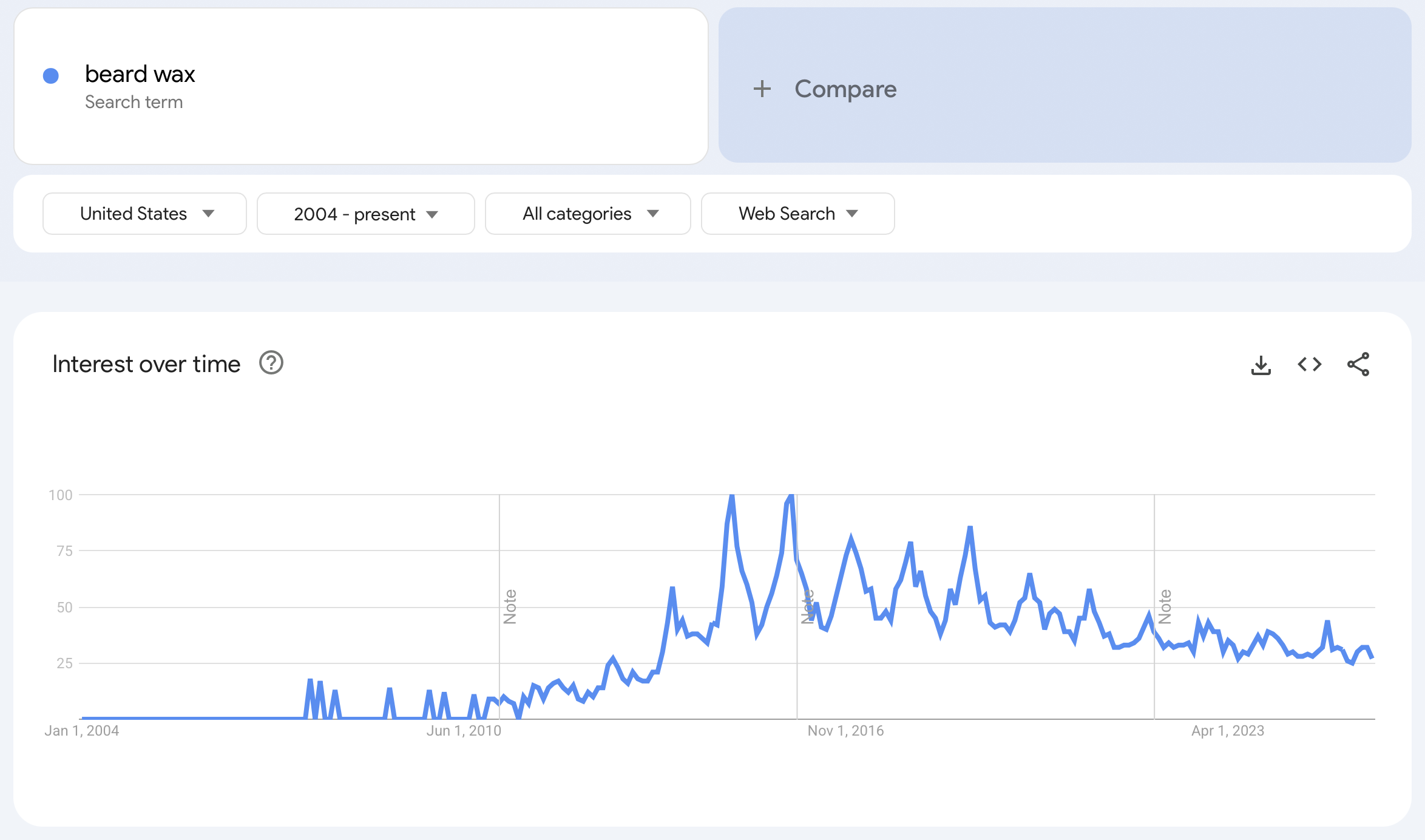
In our grocery store example, the idea of extensive sales for men's products like that of beard wax (that was not popular in the past), would make it hard for a Machine Learning algorithm to predict the success of beard wax. But the growing trend of using beard wax in the US can be seen in the Google Trends image below.
Myth 6: Machine Learning is the Objective
ML relies on data to function. It might give us the perception that it boasts objectivity. However, the data may reflect human biases in it and hold preconceptions that can produce stereotypical outcomes.
An example of this is Amazon, when it tried to use recruitment software for software development and other technical jobs. The resume data fed to the software mostly contained resumes over the past ten years, which mostly came from men. So the model concluded that male candidates were preferable over females for these positions. Later, Amazon realized the error and edited the program to have a bias-aware algorithm.
Myth 7: Machine Learning is difficult to implement in the Business
Businesses that are using ML have a competitive advantage over those that are not. Even small companies can use AI and ML to provide a better user experience to their customers.
As we know that AL and ML models need large and relevant amounts of that for training purposes. But small companies and startups do not have enough data and seldom have a high configuration system for training AL and ML models. In this case, they can use open data sources from World Bank, Data.gov, Open data sets on Kaggle and elsewhere and cloud computing resources such as AWS and AZURE to build their AI and ML model.
ML can assist you in your existing jobs to increase the productivity and efficiency of your business. We also discussed in detail in our previous chapters, the checklist to make your organization machine learning ready and what you can do to achieve it.