LLMs, Agents and What Comes Next
The rise and adoption of LLMs (Large Language Models) which in some ways an extension of neural networks has been mindboggling:
In just 5 days post launch, ChatGPT crossed 1 million users.
Two months after launch ChatGPT had 100 million users.
After 9 months since launch ChatGPT has reached 180.5 million users.
And of course these numbers do not take into account the number of users that may be using ChatGPT inside a third party product that taps into the OpenAI API or is using one of the many other LLMs.
What is a LLM?
A LLM is an Neural Network model that has trained itself on a large corpus of data (billions of parameters) and has achieved general language understanding and generation capabilities. The LLMs use statistical models and learn the relationship between words and phrases. And that is why when we interact with them, we get visions of AGI (Artificial General Intelligence, where a machine thinks like a human).
This pattern recognition aspect of a LLM can be best demonstrated by the following screenshot from ChatGPT.
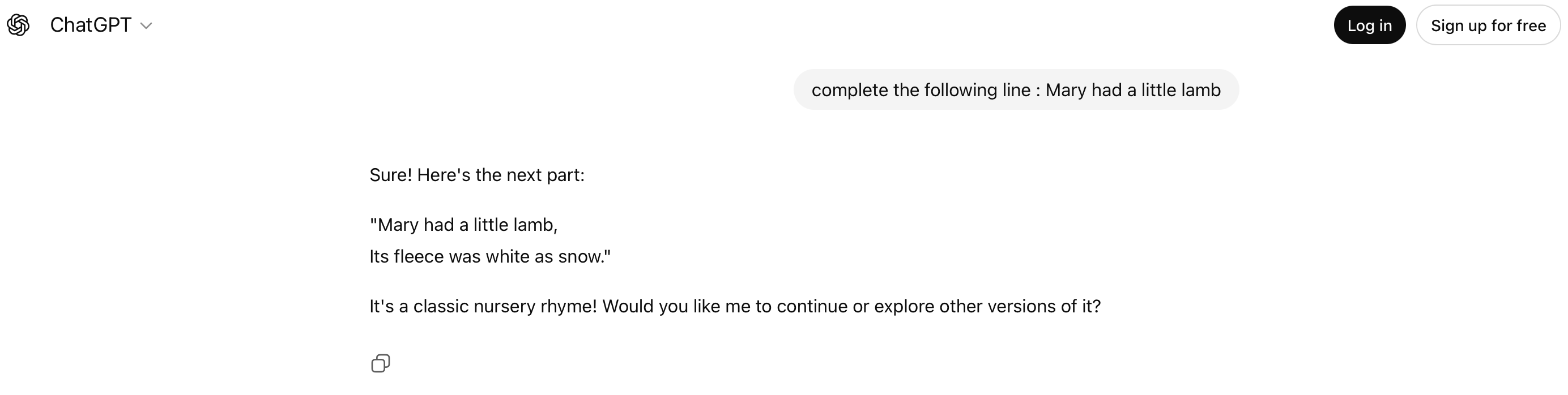
What is GPT?
It is also critical that we understand the GPT in ChatGPT. GPT stands for "Generative Pre-Trained Transformers”. GPTs are a family of models that use the “Transformer” architecture and this is what has enabled the visible improvement in humans and machines interacting today.
How does a GPT Work?

The image above provides a good representation of input text which enters the Encoder as a “prompt”. The encoder analyzes each word in the input prompt and improves upon it if required. The prompt text is vectorized i.e. converted to a numerical set of values where related words and concepts are closer to each other than un-related words or concepts.
These values then are processed by a hidden layer and outputted by a “Decoder” which transforms the vectorized numerical values back to a language that the human user understands. The hidden layer(s) contain different nodes and weights which process the inputs and help generate the output.
While an algorithm may not understand the meaning of the words it vectorizes, it does understand the relationship between words as shown in the diagram below.
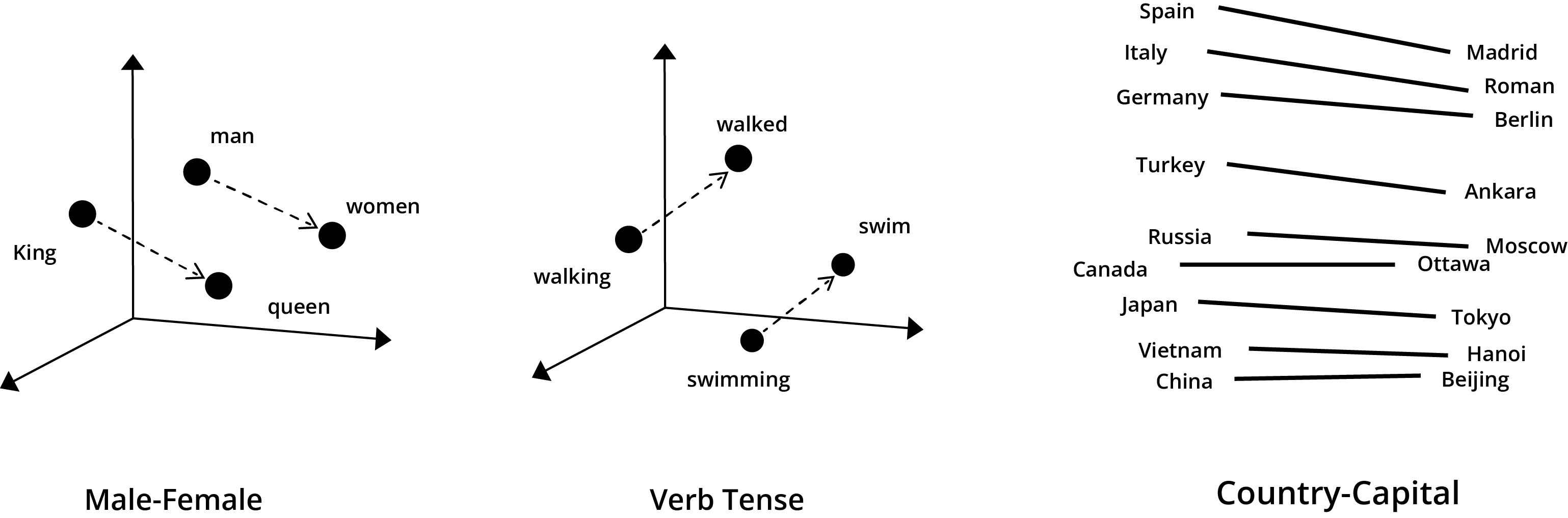
This vectorized Encoder and Decoder framework is the “Pre-Trained” part of a GPT. The G in the GPT (Generative) allows the program to “generate” new, never seen before output.
How do the LLM Models do a good job of answering your question comprehensively?
A traditional search engine takes in a keyword and then brings back some top results in its index of a passage or document that has resonated with searchers in the past or in a search engines model of ranking and relevance.
In the case of a LLM, it takes the input phrase and prepares a list of all related phrases using a “fan out” technique. This allows a LLM to be more comprehensive and confident in its response and so far it seems this approach has resonated with users too who prefer this AI way of getting responses versus having to scroll through links to get the piece of information they are after.

Drawbacks of a GPT
The creators of a GPT model suffer from an impossible choice. On the one hand they need to have a very, very, large body of training data (text in the case of non multi-modal models). And on the other hand they need to have a narrow focus so that they can convey context and understand the unique nuances of a specific domain.
The easiest way to source data at scale is by harvesting and digesting the data on the web. This gets the LLMs a lot of foundational data at scale. But with much of the world's data locked in corporate systems or behind pay walls it is no surprise that Epoch AI, the research team cited in the report, projects “with an 80% confidence interval, that the current stock of training data will be fully utilized between 2026 and 2032”.
Some key drawbacks of a LLM trained on publicly available data
1. A bias towards the English Language
The diagram below clearly shows that it is quite likely that for non English LLMs, accuracy for mission critical applications may not exist at a satisfactory level.

The same bias that exists on a language bias can be extrapolated for all other biases that exist in the human generated content. Some of these may revolve around race, gender, political views etc. may influence the LLM outputs.
2. A lack of originality
If we think of LLMs as one big algorithm that only knows what has been produced over time, you will realize that these models desperately need to know and ingest all the “new” developments that occur. If that does not happen, they will become stale.
Any new words, phrases, concepts cannot be created out of the old data. The lack of access to such information is an achilles heel of the LLMs. LLMs cannot replace original through, finding and creative representation of data (yet).
Please bear in mind that “originality” here refers to an idea or thought and not strings of text that explain the same idea again. This difference is critical to understand.
3. Hallucination
With the background that a LLM has been trained on a large amount of data that has in all likelihood been “seen” (is public on the web) and as a program it has been mandated to produce output, we must recognize that the generated output needs to be validated.
‘Hallucination’ here refers to content (especially text content) that linguistically may sound meaningful but it may not be meaningful from a domain level perspective. Here is a famous example of a hallucination from ChatGPT that has since been corrected.
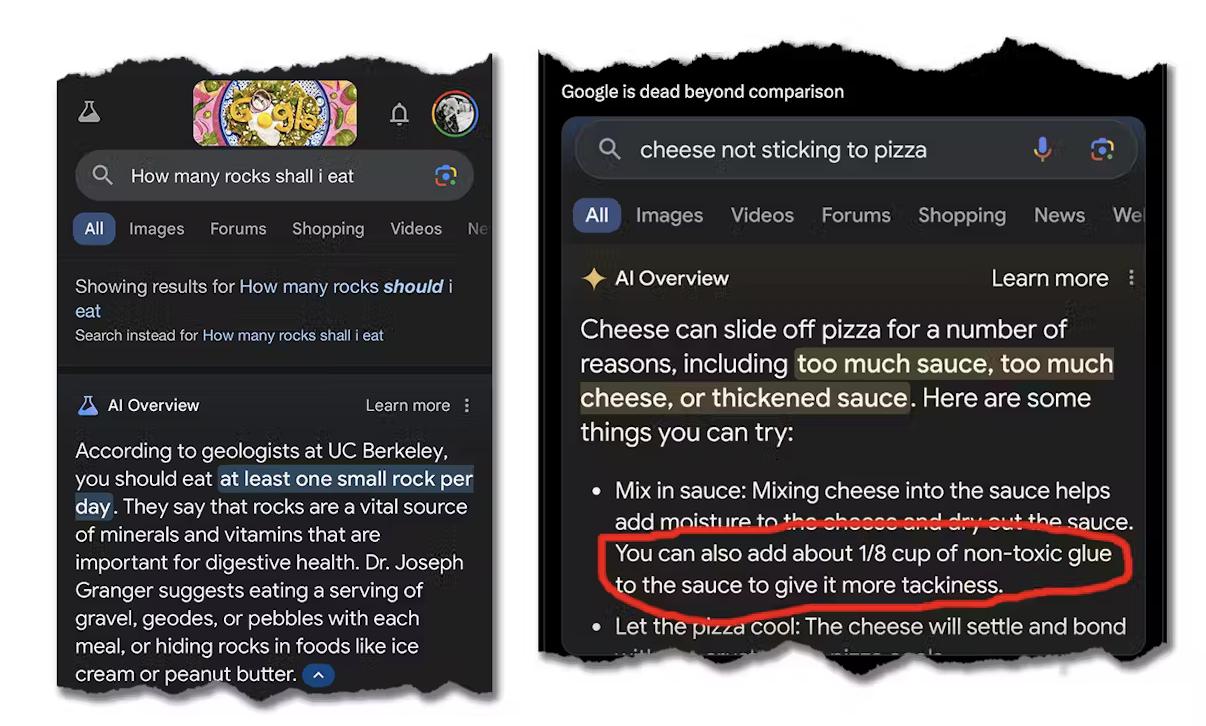
4. Operating a LLM in a silo
In order to maximize employee productivity, a LLM needs to ‘speak’ to many internal systems at a corporation. But given that LLMs need to always improve themselves, can a large enterprise be comfortable letting it into its proprietary data systems and ingesting its proprietary data?
Understanding the terms of use of a LLM is critical at corporations that have generated a large shareholder value which can be compromised. An accidental leak at Samsung where an employee uploaded code into ChatGPT is seen as a key example of how large corporations have to deal with this new risk.
Maximizing Your Productivity with a LLM
Despite these risks, LLMs are a great productivity enhancer if they can be incorporated into the work environment safely.
A way out for corporations that do not wish to train a third party LLM with their proprietary data and have greater control is having a hosted open source LLM.
This is how you can and should maximize your corporate productivity with a LLM:
A. Use an open source Transformer Models
With open source Transformer Models, you get the source code and make changes as you see fit and on your own unique business requirements.
B. Train the Transformer Model on Your Data, Your Use Cases and Your Data Sources.
Depending on the tasks you wish to automate for your employees, you can train the transformer models and create a playbook for prompts for your employees.
One of the biggest things that many users miss out on is only thinking of the likes of ChatGPT for content creation.
We need to imagine how LLM eliminates the structured language many white collar workers have to use when dealing with internal corporate systems. That is where LLMs excel when it comes to productivity.
The rise in AI powered code editors are an example of this new paradigm. As an example, when Satya Nadella stated that 30% of Microsoft's code was being written by AI, life seems to have come full circle and AI seems to be eating away the profession which gave birth to it.
C. Self host the LLM
By self hosting the entire transformer models and the proprietary data you can be in control from a security perspective.
The rise of open source LLMs (META, Mistral as an example) is a way to fight some of the early closed models developed by OpenAI, Google etc. By October 2024, META’s Llama had over 65,000 derivatives in the market showing the interest in open source models.
A notable statement from Ashok Srivastava, Intuit’s chief data officer in an interview with Venture Beat, points to how the ability to take an off the shelf module, self host it and fine tuning it can help make the model smaller and more accurate.
For customer-facing applications like transaction categorization in QuickBooks, the company found that its fine-tuned LLM built on Llama 3 demonstrated higher accuracy than closed alternatives. “What we find is that we can take some of these open source models and then actually trim them down and use them for domain-specific needs,” explains Ashok Srivastava, Intuit’s chief data officer. They “can be much smaller in size, much lower and latency and equal, if not greater, in accuracy.”
D. Create Agents
For many of the repetitive tasks that workers undertake, LLMs can be used to create Agents.
Agents can be thought of as a series of task automations written in plain language (no code) that create multiple steps in a sequence to achieve a stated goal provided by a human user. Agents have the potential to automate reports, presentations and other white collar tasks that take up a lot of time and resources as part of today's legacy work flows. Agents are becoming project team members that excel in specific roles.
Lets examine the famous UK financial services firm Schroders and their multi-agent financial analysis and research assistant. Schroders was smart enough to realize that the bulk of the time of their analysts was being spent on “data collection” and not on “insight generation”.
Given the complexity of its use case, Schroders opted to build a multi-agent system to the following characteristics:
Specialization: Designing agents which are hyper-focused on specific tasks (e.g., R&D Agent, Working Capital Agent, etc.) with only the necessary tools and knowledge for their respective domains.
Modularity and scalability: Each agent is a distinct component developed, tested, and updated independently thereby simplifying development and debugging.
Complex workflow orchestration: Multi-agent systems model their workflows as graphs of interacting agents. For example, a Porter's 5 Forces Agent designed to identify and analyze industry competition, could trigger child agents like a Threat of New Entrants Agent, in parallel or sequence, to better manage dependencies between deterministic (e.g., calculations) and non-deterministic (e.g., summarization) tasks.
Simplified tool integration: Specialized agents can handle specific toolsets (i.e., an R&D Agent using SQL database query tools) rather than having a single agent manage numerous APIs.
How do Agents connect to each other?
These “agents” need to be able to take in the output from the preceding agent and then pass on the output in a format that the next agent down the line. This is usually achieved via an open standard (Model Context Protocol or MCP) developed by Anthropic, the company behind Claude. While it may sound technical, but the core idea is simple: give AI agents a consistent way to connect with tools, services, and data — no matter where they live or how they're built.
An MCP is written in and implemented using JSON (JavaScript Object Notation) for message exchange. It is typically orchestrated in Python, since most LLM frameworks (LangChain, CrewAI, etc.) are Python-based.
Not to be left behind, Google launched its own Agent to Agent Protocol (A2A), which also enables agents to interoperate with each other, even if they were built by different vendors or in a different framework, will increase autonomy and multiply productivity gains, while lowering long-term costs.
Why do LLMs Hallucinate & How Can Their Performance Be Improved?
A. Programmed to Provide a Response
As a user of LLMs/Chatbots, we must realize that the LLMs are programmed to provide a response. That is their default behavior. This occurs even if they don't know much about a topic, they will provide a response whether it is grounded in deep knowledge or not.
B. Limited Short Term Memory
LLMs do not have a concept of a long term memory during a chat. At various points, the LLM chatbot “forgets” about the earlier part of the conversation and this also contributes to inaccuracies in their answers. This is why many LLMs choose to differentiate themselves on the basis of a long context window.
A context window is the amount of information a language model can “see” and understand at one time when answering your question. You can think of the context window as a short term memory.
As a user we cannot repeatedly refine what is in the context window across several elements of a chat as we are bound to run into context window limitations sooner or later.
C. Lack of Long Term Memory
Unlike a human, LLM chatbots do not “hold” memory across different chat sessions. Clearly this is a problem for enterprise solutions or solutions where accuracy is required.
To solve long term memory issues, the only possible solution is to store the key pieces of information in an external storage mechanism.

LLMs and Long Term Memory
It is not feasible for a LLM to go over all the data stored in a long term memory storage system every time you ask it a question. The compute time for such an exercise would be too onerous.
In order to ensure that we have an efficient means for the LLMs to operate with Long Term Memory storage mechanisms, we need to use a few different techniques that help balance accuracy and efficiency.
Some of these main techniques are as follows:
A. RAG (Retrieval-Augmented Generation)
In a RAG operation, a user enters a query which is run against a vector database. A vector database is the external storage mechanism where all the relevant data has been converted to a numerical format. This is done via an “embedding model” and in many cases if you use off the shelf vector databases, you may not be aware of which “embedding” model may be used in the background.
Unlike a traditional database, a vector database stores and searches chunks of documents by their similarity.
The prompt/query retrieves the most relevant passages of the responses (the "retriever' part of the RAG).
Once several such “chunks” have been found, the LLM (the “generator” part of the RAG) constructs that response for the user.
This kind of a basic RAG is best suited to processing text content.
B. Extended RAG
Data can come in all formats and styles.
Where the data may include diagrams, images and the text contact is sparse, the vector database needs to be augmented with OCR/labelling. Without this a traditional RAG approach may suffer.
Where the content may include spreadsheets, the data may have to be flattened and pre-processed using Pandas (a Python library used for data analysis). Other data formats may require other types of pre-processing.
C. Graph RAG
Sometimes in data sets, we have “entities” that have relationships between them. As an example, think of a dataset that contains elements from the Periodic table and when specific elements are combined they lead to a specific kind of a reaction.
In such a case, instead of relying on a traditional RAG approach, it would be beneficial to establish relationships between several elements of a data set. This allows for structured retrieval, deeper reasoning and reduced hallucination. Tools like LlamaIndex, Haystack and Neo4jETL etc. can be used in GraphRAG.
Here is a high level summary of some of the major RAG variants:
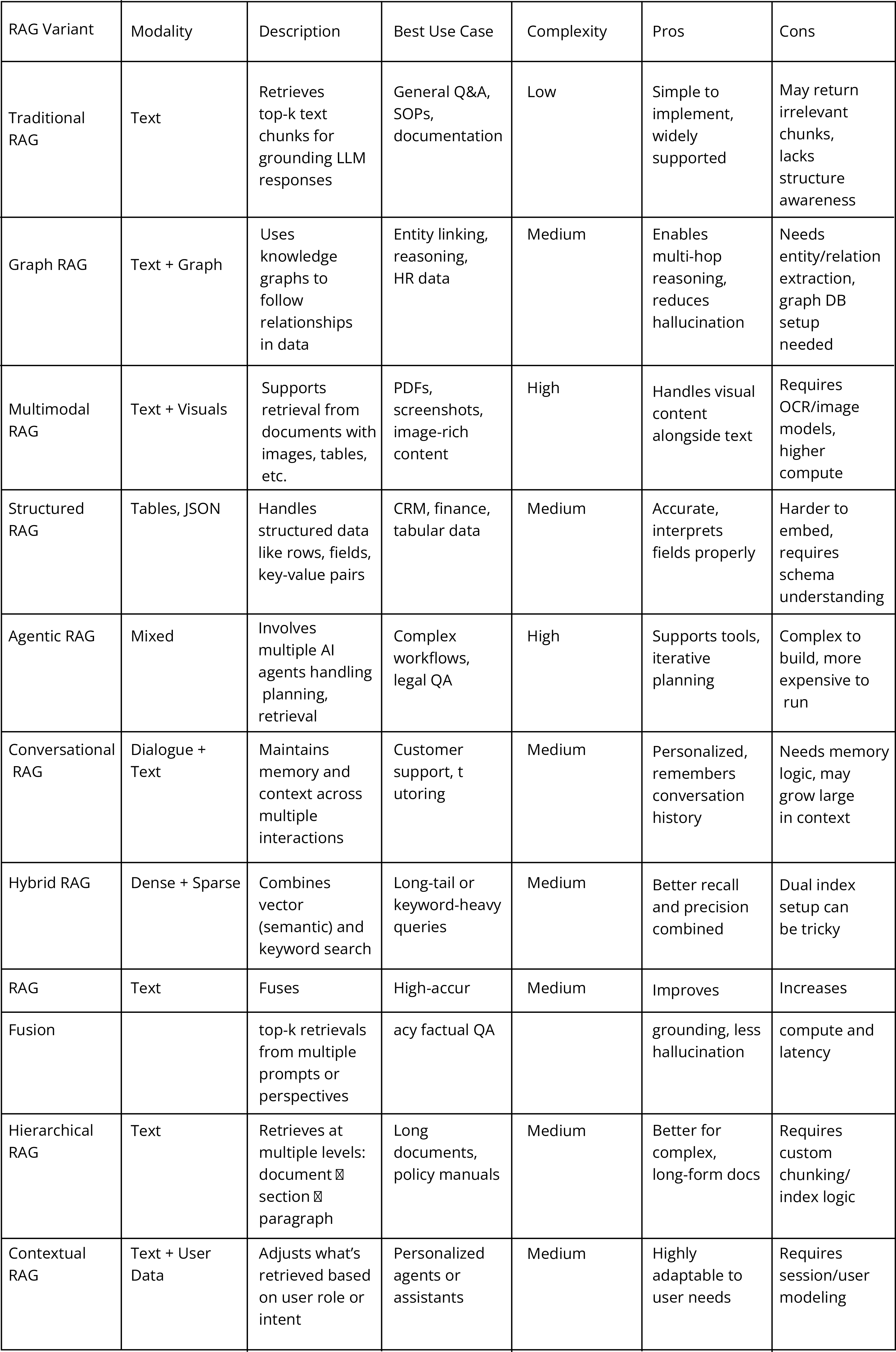
How can a business adapt a LLM for their business effectively?
All LLMs have been trained on vast amounts of data which has been sourced from the web. This means that the domain knowledge for any specific business is diluted across many other verticals.
A key way to fine-tune an existing LLM with LoRA (Low-Rank Adaptation) — without needing to retrain the entire model.
LoRA is a technique that inserts small, trainable layers into a frozen pre-trained model. Instead of modifying all model weights, it updates only a few low-rank matrices.
Think of it like this:
The main model stays frozen
You plug in a lightweight adapter
You train just that adapter
Weights are the learned parameters of a neural network. They are like knobs that control how much influence different pieces of input have on the output. In an LLM, weights are the "memory" — they determine how the model understands language.
Weights are found in:
Attention layers (how words relate to each other)
Feed-forward layers (basic computations between tokens)
Embedding layers (mapping words to vectors)
Output layers (predicting the next word)
The Agentic Landscape
As the world moves towards an agentic landscape and perhaps viewing the rise of open LLMs, Google launched its own open source initiative of the Agent Development Kit (ADK). ADK is a Python based open source framework that offers a full stack end-to-end development of agents and multi-agent systems. Together with the A2A Protocol, Google has also entered the “open” and “collaborative” AI initiatives.
Where do we go from here?
Here are a few key developments in the AI space that have begun to make their appearance felt in the AI space.
A. From task automation to workflow automation
We are quickly moving from a task automation stage towards “workflow” automation. This magnifies the impact of the changes.
B. The rise of SMOL agents
Smol Agents (short for Small Agents) are lightweight AI agents designed to perform specific, narrowly focused tasks efficiently — often with minimal compute, memory, or resource requirements.
This may mean we will probably see more AI processing happen locally on a user's mobile device where AI models are embedded into apps versus being hosted elsewhere.
C. AI powered browsers
New browsers like Comet from Perplexity can be connected by a user to their email, calendar, drive of documents, email. With these connections, the browser can execute on personalized automation at scale.
Have you thought about what you will be automating at scale and how you will ride the next wave of productivity heading our way.